As corporate cloud storage grows, the Data Gravity effect intensifies — a phenomenon where large data volumes attract computational processes. When terabytes and petabytes of datasets concentrate in a single S3-compatible storage region, workloads such as ETL pipelines, analytics, and AI inference naturally “settle” closer to the data source to reduce latency and traffic costs.
As cloud storage scales into terabytes and petabytes, data placement becomes a dominant architectural factor. Data Gravity explains why computation increasingly moves toward data — not the other way around — reshaping cloud architecture, network design, and AI workload placement.

For Serverspace with multiregion networks (RU, IO, US, KZ, etc.), this effect is critical when scaling AI workloads: high density of S3 data access and the need for synchronous access to neural network weights drive Kubernetes clusters and BI services toward regions with minimal latency and maximum throughput. Data Gravity becomes not just a theoretical concept, but an observable factor directly impacting application performance, network architecture, and financial efficiency of distributed infrastructure.
What is Data Gravity in Simple Terms
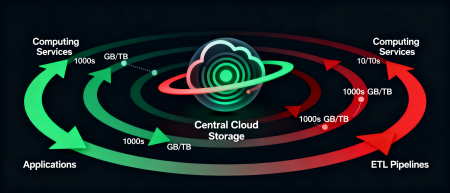
At its core, Data Gravity describes the economic and physical resistance to moving large datasets across infrastructure boundaries.
Data Gravity is a concept describing how large data volumes create an "attraction" for computational processes, applications, and services. The more data stored in a particular infrastructure and the higher the frequency of access to that data, the more complex and expensive it becomes to move or process that data outside its location.
In cloud system terms, this means that when attempting to run computations in another region or cloud, additional network delays, excessive bandwidth consumption, and direct financial costs arise. For example, if a Serverspace ETL pipeline accesses data stored in an S3-compatible storage in region RU and attempts to process it in AWS Lambda in region
us-east-1, performance degrades significantly due to network lag, inter-cloud data replication, and the need to re-synchronize results.
This effect manifests not only in cloud environments but also in local Data Warehouses and on-premise solutions: the larger the data volume, the higher the cost and time required to move it, forcing engineers to place computations as close as possible to the data source at the physical architecture level.
How the Effect Manifests in Infrastructure
In Serverspace infrastructure, the Data Gravity effect manifests particularly sharply when working with large volumes in S3-compatible storage and multi-regional scenarios. Technically, this is observed through increasing network delays (latency) and declining available bandwidth between zones — for example, RU, NL, KZ — as the total data volume, operation intensity, and number of concurrent requests increase.
Key technical manifestations of Data Gravity:
- Inter-regional latency and performance degradation. When moving large buckets (e.g., from 100 GB to 3 TB), average data access delays over the network can increase from 38 ms to 80–90 ms even between relatively close regions due to router congestion, increased packet fragmentation, and the need to retransmit lost data. Intercontinental latency between datacenters in Europe, Russia, Kazakhstan, and other locations is even higher (200–500 ms) and exponentially sensitive to the volume of operations per second, data types, and network congestion.
- Outbound traffic growth, traffic costs, and financial expenses. In distributed computing, additional network costs arise for each inter-regional data packet, especially if datasets are "spread" across different clusters or storage zones. This requires careful financial accounting — for instance, internal traffic between Serverspace virtual machines and object storage in a single availability zone is not charged, while external inter-regional traffic increases load costs by 50–200% depending on the route direction.
- I/O performance, pipelined operations, and consolidation. The closer data is placed to computations (ideally in a single availability zone), the higher the overall throughput through reduced RTT (round-trip time) and better CPU cache utilization. There's less chance of bottlenecks during simultaneous ETL, ML pipeline, and BI workload operation. Attempting to replicate or actively synchronize large volumes between regions results in noticeable replication delays (replication lag) up to several minutes with mass changes and high write operation frequency.
Modern scenarios working with large files (video archives, large language model weight coefficients, log archives for security analytics, genomic datasets) show that latency-sensitive services must consolidate where the main "gravitational" data mass resides — typically within a single region or even a single accessible storage zone within a region to minimize delays by hundreds of milliseconds.
How AI Workloads Intensify Data Gravity
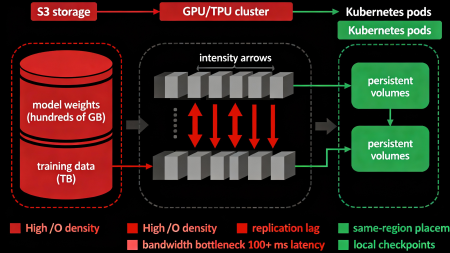
Modern AI workloads significantly intensify the Data Gravity effect in Serverspace infrastructure through extremely high intensity of access to massive datasets and critical need for low access delay at the microsecond level.
- High I/O density and bandwidth-bound computing in generative models. Generative models require frequent and volumetric reading of large parametric weights (from hundreds of gigabytes to several terabytes) and training datasets, resulting in extremely high I/O operation density. Inference of large language models with hundreds of gigabytes of weights is physically impossible without localizing resource-intensive data as close as possible to computational nodes (GPU/TPU) due to network lag that can reach 100+ ms per model pass and critical bandwidth limitations of 10–40 Gbps between regions.
- ML pipelines, tight coupling with storage, and persistent state. Model training, inference, and log analytics in ML pipelines are executed with frequent data exchange (checkpoints, model updates, gradient synchronization), creating high replication lag with remote storage. Kubernetes clusters with persistent volumes tightly bind execution containers and pods to specific regions where data resides to minimize latency and prevent bottlenecks during horizontal scaling and distributed training.
- Regional dependencies, exponential traffic costs, and vendor lock-in. Each inter-regional call to object storage increases outbound traffic, directly increasing cloud budget expenses (often exponentially with PB-scale data). Serverspace's specific egress traffic pricing requires optimization of placement architecture so AI workloads are processed exclusively in regions with high data density, minimizing overhead network and financial costs of 10,000–100,000 USD per month for large companies.
Thus, AI queries and ML processes not only exploit Data Gravity but amplify it exponentially: computations and data become "tightly coupled" through tight dependencies at the network protocol level (TCP, UDP, QUIC), operating systems (kernel buffers, page caching), and cloud services (availability zones, network policies), requiring a comprehensive and proactive approach to regional placement and traffic optimization.
Methods for Mitigating Data Gravity Effect in Serverspace
Serverspace employs a comprehensive set of modern methods and architectural patterns that minimize the negative consequences of Data Gravity and increase efficiency when working with distributed data and AI workloads:
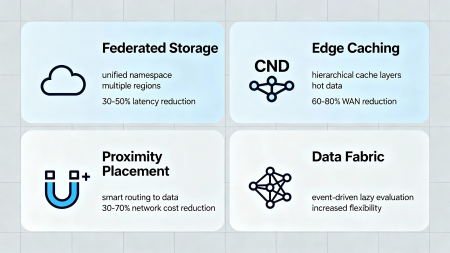
- Federated Storage and multi-cloud orchestration. Flexible consolidation of object storage across different Serverspace regions enables creating a unified virtual environment with a standardized namespace where data physically resides in multiple locations (RU, NL, KZ) but is logically accessible as a single resource through a unified API. This reduces latency, simplifies access management, and allows computations to "settle" closer to data, minimizing inter-regional traffic while maintaining placement flexibility.
- Edge caching and hierarchical caching layers. Using intermediate CDN nodes and local cache-layers to cache frequently requested data (hot data) accelerates response and significantly reduces load on primary storage and WAN channels. This is critical for analytical and BI queries with high read intensity (100+ RPS), allowing data to be brought closer to consumers by 50–200 km through edge nodes without needing full data array replication to each region.
- Multiregion replication with proximity-placement and smart routing. Automatic placement policy for workloads in regions as close as possible to primary dataset storage reduces network delays by 10–50 ms and outbound traffic costs by 30–70%. This is achieved through proximity-placement mechanisms and intelligent routing, distributing computational jobs based on data location, current network congestion, and Serverspace physical infrastructure specifics.
- Data Fabric architecture with intelligent orchestration. This architecture employs a unified data bus (data mesh or data platform) providing transparent and asynchronous interaction between AI streams, ETL processes, and microservices, enabling flexible management of data movement, transformation, and caching, minimizing redundant transfers and optimizing network channel and storage load through event-driven architecture and lazy evaluation.
These methods combined enable Serverspace not only to effectively combat Data Gravity limitations but to build an entirely new paradigm — "intelligent gravity," where computations and data are intelligently distributed and oriented close to each other based on ML predictions, ensuring maximum performance and financial efficiency at scale.
Recommendations for Architects
When designing and optimizing cloud architecture considering the Data Gravity effect in Serverspace, it's important to approach AI workload and data placement systemically and proactively to achieve maximum performance, scalability, and cost optimization throughout the application lifecycle.
- Plan AI workloads federally, not monoithically. Distributing computational tasks across multiple regions considering proximity to data and current network conditions helps reduce latency by 20–40% and decrease outbound traffic by 30–50%, which is critical for scalable ML and BI scenarios. It's recommended to use data-affinity scheduling in Kubernetes and smart load balancing between regions.
- Implement detailed monitoring of throughput, latency, replication lag, and network congestion. It's important to establish comprehensive observability and monitor bandwidth between regions, data replication time, packet loss rate, and CPU/memory utilization at the network level to timely identify bottlenecks and adapt computational resource placement strategy. It's recommended to integrate metrics into Prometheus/Grafana and configure automatic alerts when thresholds are exceeded.
- Account for FinOps aspects of Data Gravity and cost optimization. When planning cloud infrastructure budget and costs, you must account for additional inter-regional traffic expenses (30–50% of baseline cost when scaling), replication, and standby resources, especially when scaling AI workloads and working with petabyte-scale multiregion storage. Architecture optimization should balance latency (target < 50 ms), throughput (target > 500 Mbps), and cost (target < $0.05 per GB per month) through tiered storage, cold data archival, and intelligent caching.
Thus, successful management of the Data Gravity effect requires a comprehensive, data-driven, and financially-conscious approach to architecture, including proper data and computation placement, detailed network and financial monitoring, and continuous optimization and adaptation to changing business requirements.
The Data Gravity effect is not a design flaw or cloud infrastructure deficiency, but a natural and inevitable consequence of growing data volumes in modern distributed cloud systems. The larger and denser data storage becomes, the stronger computational processes are literally "pulled" toward their location at the level of network physics and cost economics, directly impacting application architecture, network topology, performance parameters, and financial costs.
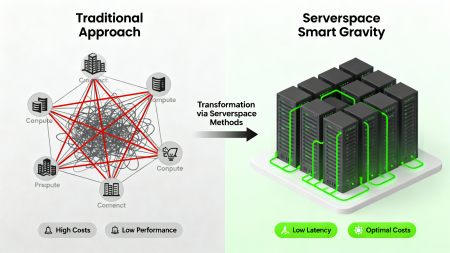
Serverspace, considering the specifics of growing AI workloads, low-latency requirements, and the scale of multiregion storage, offers effective and innovative mechanisms for managing this effect — from federated storage and multi-level edge caching to intelligent proximity-placement and unified Data Fabric architecture. This enables creating a paradigm of "intelligent gravity" where data and computations are purposefully oriented and direct each other toward locations achieving minimum network latency, maximum throughput, and optimal cost-to-performance ratio.
Deep understanding and proactive management of the Data Gravity effect becomes a key success factor in building scalable, high-performance, reliable, and cost-effective cloud solutions meeting ambitious modern business requirements, rapidly growing AI applications, and critical data processing systems in Serverspace.
In practice, Data Gravity defines where systems can scale — and where they inevitably fail.
FAQ: Data Gravity in Cloud Storage
- What causes Data Gravity?
Large data volumes, frequent access, and high outbound traffic costs. - Why is Data Gravity critical for AI workloads?
Because AI models require low-latency access to massive datasets and model weights. - How can Data Gravity be reduced?
By placing compute close to storage, using caching layers, and minimizing inter-regional traffic.


