
Einleitung
Im Serverspace Sie uns Erstellen Sie einen Server mit bereits installierter App „MongoDB“.
MongoDB ist eine der beliebtesten NoSQL-Datenbankverwaltungslösungen. In KombinatIon mit Kubernetes Orchestrator könnte es sich um eine einfach zu skalierende, vielseitige Lösung handeln.

Voraussetzungen:
Um mit MongoDB zu arbeiten Kubernetes Sie benötigen einen Server unter jedem Betriebssystem (Linux mit Root-Zugriff oder Sudo-Mitgliedschaft bevorzugt) zum Verwalten und Kubernetes Cluster (siehe nächster Schritt).
Kubernetes Instanzerstellung
Bevor Sie MongoDB bereitstellen können, benötigen Sie Folgendes Kubernetes. Um es zu erstellen ServerSpace Infrastruktur, melden Sie sich einfach bei Ihrer an cliHNO-Bereich also click zu Kubernetes verknüpfen und eine Instanz erstellen:
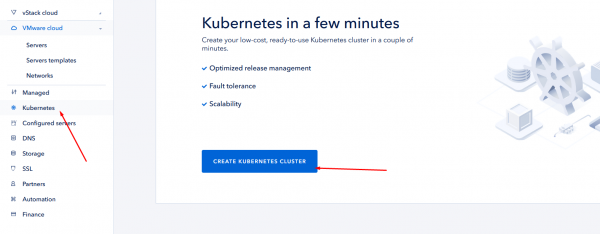
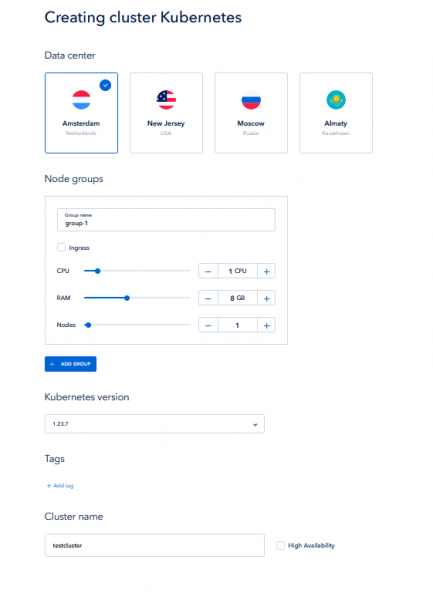
Der Vorgang kann einige Zeit dauern. Bitte haben Sie etwas Geduld. Wenn Sie fertig sind, wird Cluster pa angezeigtrameters und sollte die Zugangsberechtigungsdatei herunterladen:
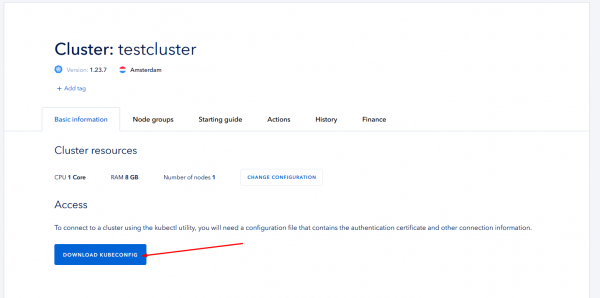
Instanz-Setup
So installieren Sie den Datenbankdienst auf Ihrem Kubernetes Cluster folgen Sie bitte:
- Melden Sie sich als privilegierter Benutzer bei Ihrem Verwaltungsserver an und installieren Sie die erforderlichen Tools:
sudo -s
apt-get update && apt install curl apt-transport-https -y && curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - && echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" | tee -a /etc/apt/sources.list.d/kubernetes.list && apt-get update && apt install kubectl -y
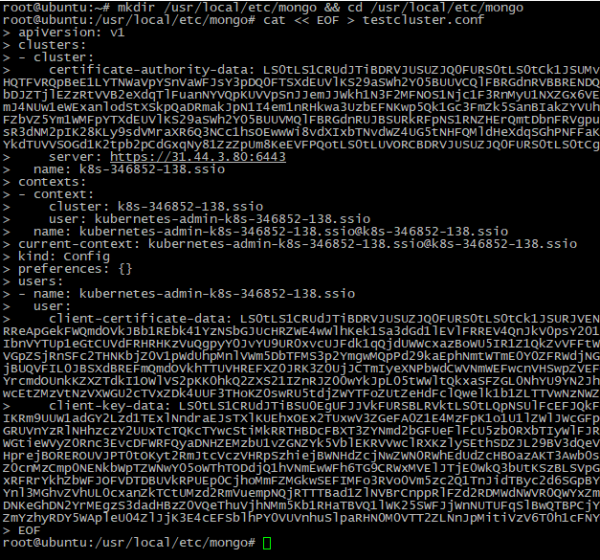
- Erstellen Sie eine Datei, die Cluster-Zugriffsdaten speichert, und legen Sie diese als Systemvariable fest:
mkdir /usr/local/etc/mongo && cd /usr/local/etc/mongo
cat << EOF > testcluster.conf
<PASTE CONFIGURATION DATA HERE>
EOF
echo "export KUBECONFIG=testcluster.conf" >> ~/.bashrc
- Um die Verbindung zu überprüfen, führen Sie einfach Folgendes aus:
kubectl cluster-info
Wenn die Ausgabe wie im Bild unten aussieht, ist die Verbindung erfolgreich

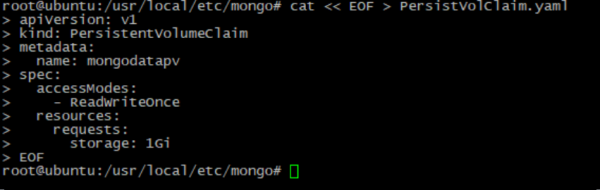
- MongoDB benötigt Speicher, um seine Daten zu speichern. Der Speichererstellungsprozess wird in speziellen Konfigurationsdateien beschrieben. Sie können es an Ihre Bedürfnisse anpassen:
cat << EOF > PersistVolClaim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodatapv # Should be the same with name in previous file
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi # Should be the same with capacity in previous file
EOF
Der nächste Schritt besteht darin, eine Anmeldeinformationsdatei zu erstellen, die den Zugriff auf MongoDB speichert:
cat << EOF > Creds.yaml
apiVersion: v1
data:
username: <BASE64_ENCODED_LOGIN>
password: <BASE64_ENCODED_PASSWORD>
kind: Secret
metadata:
creationTimestamp: null
name: creds
EOF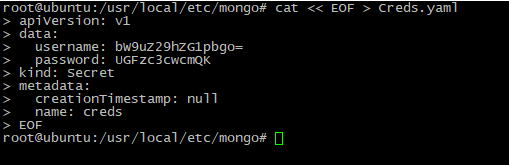
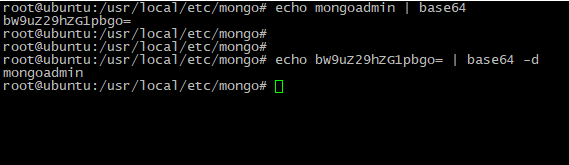
Tipp: Zum Kodieren und Dekodieren von Daten können Sie einfache Befehle verwenden:
echo <DATA> | base64 # to crypt data via base64 tool
echo <BASE64_ENCRYPTED_DATA> | base64 -d # to decrypt it
- Erstellen Sie dann eine Instanzbereitstellungsdatei:
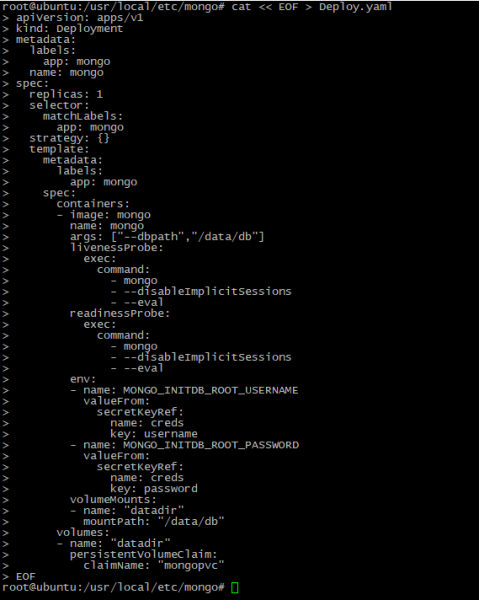
cat << EOF > Deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: mongo
name: mongo
spec:
replicas: 1
selector:
matchLabels:
app: mongo
strategy: {}
template:
metadata:
labels:
app: mongo
spec:
containers:
- image: mongo
name: mongo
args: ["--dbpath","/data/db"]
livenessProbe:
exec:
command:
- mongo
- --disableImplicitSessions
- --eval
readinessProbe:
exec:
command:
- mongo
- --disableImplicitSessions
- --eval
env:
- name: MONGO_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: creds
key: username
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: creds
key: password
volumeMounts:
- name: "datadir"
mountPath: "/data/db"
volumes:
- name: "datadir"
persistentVolumeClaim:
claimName: "mongopvc"
EOF
- Um MongoDB zu starten, führen Sie bitte den folgenden Befehl aus:
kubectl apply -f
Eine erfolgreiche Ausgabe sieht wie im Bild unten aus:

Verbindungsprüfung
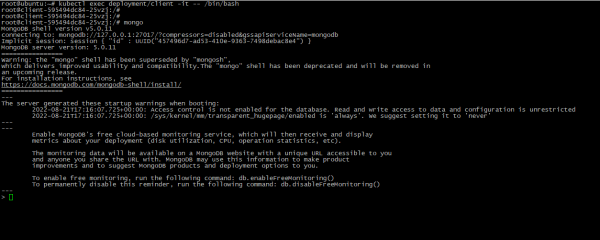
- Da die Instanzen nun bereitgestellt sind, sollten Sie die Verbindung überprüfen. Lauf einfach:
kubectl exec deployment/client -it -- /bin/bash
mongo
Wenn Sie die MongoDB-Eingabeaufforderung sehen, ist die Verbindung erfolgreich:
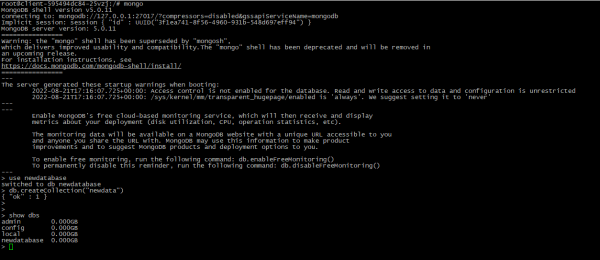
- Um eine neue Datenbank zu erstellen, „wechseln“ Sie einfach zur neuen Datenbank. HINWEIS: Daten werden erst gespeichert, wenn Sie etwas zur Datenbank hinzufügen:
use NEW_DATABASE_NAME
db.createCollection("newdata") # example to add data
show dbs # check is database exist
Zusammenfassung
Nachdem Sie diesen Artikel gelesen hatten, wussten Sie, wie man erstellt Kubernetes ServerSpace client-Bereich, stellen Sie MongoDB darin bereit, erstellen Sie eine neue Datenbank und fügen Sie neue Daten in diese Datenbank ein.


